云原生大数据系统架构的实践与思考 数栈技术专家的深度分享
随着企业数字化转型的深入,传统大数据平台在弹性、运维成本和资源利用率等方面的挑战日益凸显。云原生技术以其弹性伸缩、敏捷交付和高效运维的特性,为大数据系统架构带来了革命性的变革。作为数字技术服务领域的前沿实践者,数栈技术团队在云原生大数据系统架构方面积累了丰富的经验,并在此分享我们的实践与思考。
一、云原生与大数据融合的核心价值
云原生大数据架构的核心在于将大数据组件(如Hadoop、Spark、Flink)与云原生的容器化、微服务和声明式API等理念深度融合。这种融合带来了多重价值:通过Kubernetes等容器编排平台,实现计算与存储资源的弹性伸缩,有效应对业务峰值;利用容器化部署简化环境一致性管理,提升开发与运维效率;借助服务网格和可观测性工具,增强系统的可维护性与故障恢复能力。
二、实践路径:从传统架构到云原生演进
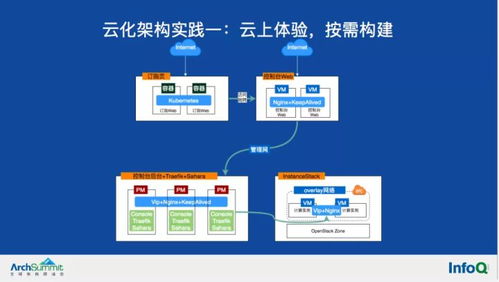
我们的实践并非一蹴而就,而是经历了循序渐进的演进过程。初期,我们在保留HDFS等存储层的将计算框架(如Spark作业)容器化并部署在Kubernetes集群上,实现计算资源的池化与弹性。逐步引入对象存储替代部分HDFS场景,降低存储成本。在进阶阶段,我们采用Operator模式自动化管理大数据组件(如Flink Operator),并利用Istio服务网格优化服务间通信。这一过程中,我们注重兼容现有业务,确保平稳过渡。
三、关键挑战与解决方案
在实践过程中,我们遇到了诸多挑战。例如,大数据任务对网络和本地存储的性能要求较高,我们通过优化Kubernetes网络插件(如使用Cilium)和采用本地持久卷(Local PV)来提升I/O性能。另外,多云和混合云环境下的数据一致性也是一大难点,我们通过元数据统一管理和数据同步工具链来保障。安全与合规性不容忽视,我们集成了云原生安全工具(如OPA),实现细粒度的访问控制。
四、未来思考:智能化与开放生态
云原生大数据架构将朝着更智能、更开放的方向发展。一方面,AI驱动的自动扩缩容和故障预测将成为标配,进一步提升系统自治能力;另一方面,开放架构将促进多引擎(如数据分析、机器学习)的统一编排,避免厂商锁定。作为数字技术服务提供者,我们建议企业根据自身业务场景,采用渐进式策略,并积极拥抱社区标准(如CNCF项目),以构建可持续演进的大数据平台。
云原生大数据系统架构不仅是技术升级,更是企业数据驱动能力的基石。通过持续实践与思考,数栈技术团队愿与业界同行一道,推动数字技术服务向更高效、更智能的未来迈进。
如若转载,请注明出处:http://www.jnpghnr.com/product/80.html
更新时间:2026-06-19 07:51:26